
 |
Home ▼ Bookkeeping
Online ▼ Security
Audits ▼
Managed
DNS ▼
About
Order
FAQ
Acceptable Use Policy
Dynamic DNS Clients
Configure Domains Dyanmic DNS Update Password Network
Monitor ▼
Enterprise Package
Advanced Package
Standard Package
Free Trial
FAQ
Price/Feature Summary
Order/Renew
Examples
Configure/Status Alert Profiles | ||
| Survey Data Mining: Home | FAQ | Archive | Glossary |
|
Free Reports |
|
| Report Description |
As a result, some web servers that may not rank very high on our regular survey, may rank highly here, if they are used by very well known, highly referenced web sites. As the number of websites change (top 50, top 250 and top 1000 websites from our survey), the results are also very interesting and different.
| Weighed Web Server Share - Top 50 Sites |


| Web Server | Share |
| Apache | 41.16% |
| Microsoft-IIS | 15.67% |
| Not Known | 14.29% |
| Netscape-Enterprise | 11.48% |
| Stronghold | 3.92% |
| NaviServer | 3.25% |
| GWS | 2.62% |
| Zeus | 1.72% |
| Roxen | 1.57% |
| AV | 1.39% |
| AOLserver | 1.24% |
| Spry-SafetyWEB-Serve | 0.85% |
| DCLK-HttpSvr | 0.84% |
| Weighed Web Server Share - Top 250 Sites |

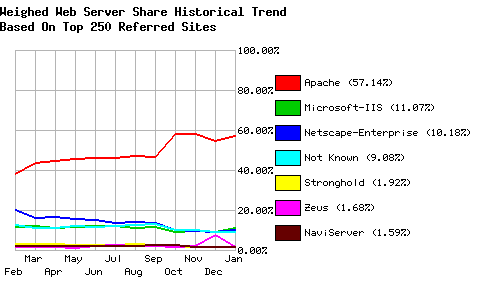
| Web Server | Share |
| Apache | 57.14% |
| Microsoft-IIS | 11.07% |
| Netscape-Enterprise | 10.18% |
| Not Known | 9.08% |
| Stronghold | 1.92% |
| Zeus | 1.68% |
| NaviServer | 1.59% |
| GWS | 1.28% |
| AOLserver | 1.06% |
| AV | 0.98% |
| Roxen | 0.77% |
| 0W | 0.68% |
| AkamaiGHost | 0.55% |
| Spry-SafetyWEB-Serve | 0.42% |
| DCLK-HttpSvr | 0.41% |
| IBM_HTTP_Server | 0.25% |
| ConcentricHost-Naram | 0.25% |
| Resin | 0.25% |
| Carpe | 0.23% |
| Y.G.Apache-SSLv3 | 0.22% |
| Weighed Web Server Share - Top 1000 Sites |


| Web Server | Share |
| Apache | 53.99% |
| Microsoft-IIS | 13.10% |
| Netscape-Enterprise | 11.07% |
| Not Known | 7.38% |
| Zeus | 3.82% |
| Stronghold | 2.07% |
| NaviServer | 1.00% |
| GWS | 0.91% |
| AkamaiGHost | 0.81% |
| AV | 0.77% |
| AOLserver | 0.70% |
| Roxen | 0.52% |
| IBM_HTTP_Server | 0.40% |
| 0W | 0.38% |
| DCLK-HttpSvr | 0.36% |
| thttpd | 0.26% |
| Spry-SafetyWEB-Serve | 0.23% |
| Resin | 0.23% |
| MIT | 0.16% |
| Oracle9iAS | 0.15% |
| Methodology |
Our goal with this report is to get closer to answering the question of how much traffic is served up on the internet by various servers than a typical web server count would reveal. We want to distinguish between a highly trafficed portal and a site that has only a couple visitors per month.
Since we don't have access to the actual traffic logs from all the different web servers in question, we focused on a different technique to determine the popularity of servers. The technique measures how authoritative a web server appears to be on the internet by how often it is referenced by other sites. The idea is that a server that is referenced by hundreds or thousands of sites wil in general have much more traffic than a web server that is referenced only a hand full of times, or not at all.
Our survey each month reports on the most popularly referred sites, which we call the popular referral report. This gives us a measure of how authoritative a site is. By combining this information with our existing knowledge of what server is running at the site in the report, we build a ranking of web servers based on referral popularity.
The scoring algorithm goes as follows:
This is process is done 3 times, once for the top 50 sites, once for the top 250 sites, and once for the top 1000 sites. The percentages shown assume that the sites examined - 50, 250 or 1000 respectively - carried all internet traffic. While this is clearly not the case, the percentages are at least accurate relative to each other.
Finally, remember that the referral report (and thus how authoritative a site is) is based on a sample of the web. There is an inherent limitation in this report, which causes some site's referral count to be higher than warranted. Usually, this is a result of a suite of portals, all operated by the same group, each that refers to all the others. The effect of this is to lend a higher than justified weight to some sites. This results in a spiky historical trend line in the weighed graphs.
This problem is exasperated by the fact that our general crawler, up to and including the August 2000 survey, crawled our known list of sites alphabetically. This caused several of these portal "suites" to be clustered together due to their names. As of September 2000, the crawler has been randomized to limit the impact of this problem.
Because of the above problems, we recommend that the graphs be interpreted
by paying limited attention to spikes in the graph, and more attention to
general trends, such as server X appears to have
more share than server "Y" when examined over the course of an 3-4 months.